laion-datasets
LAION-Aesthetics V1
Laion aesthetic is a subset of laion5B that has been estimated by a model trained on top of clip embeddings to be aesthetic. The intended usage of this dataset is image generation.
Normal results:

Aesthetic results:
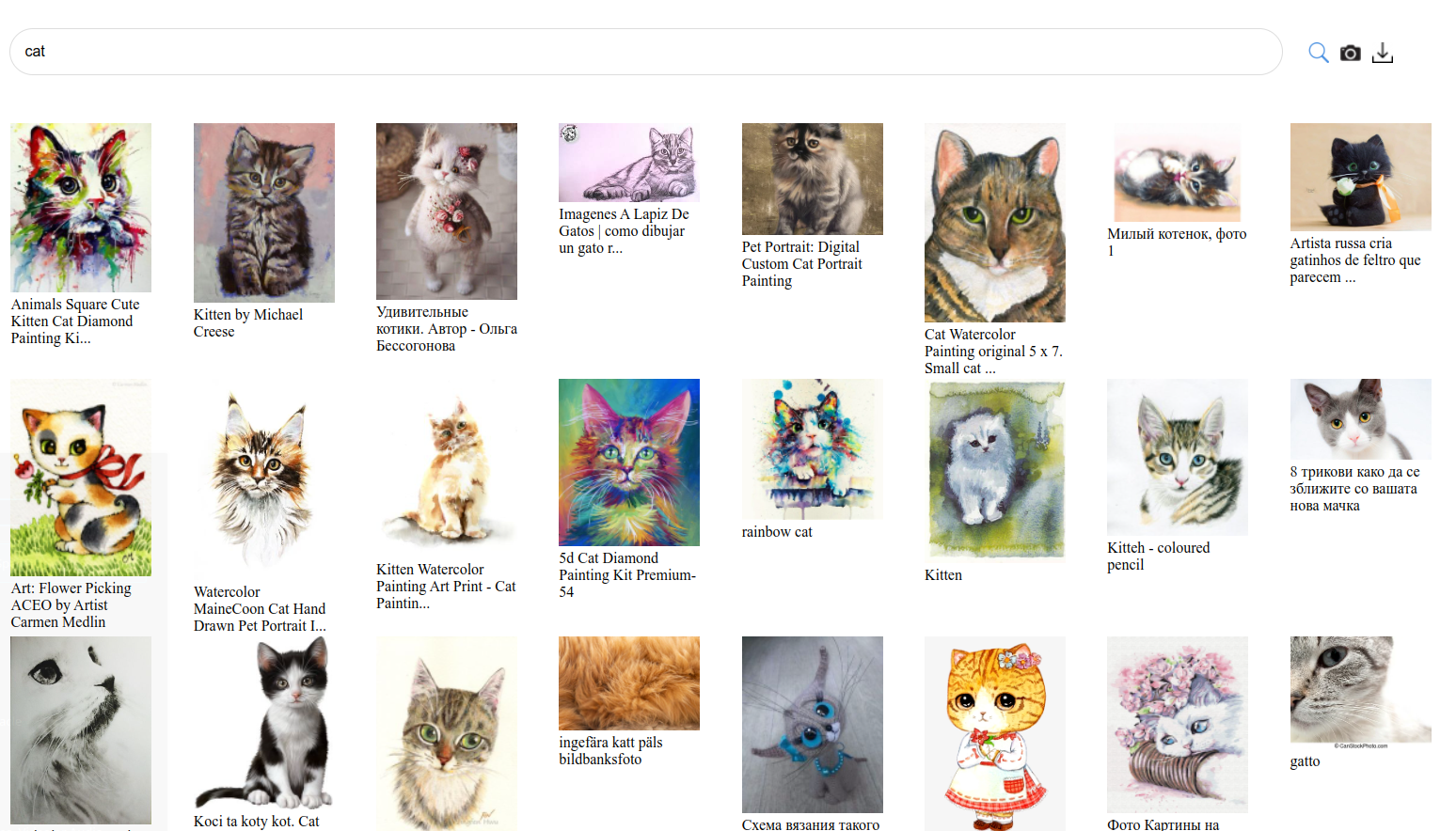
2000 random samples from the >= 7 aesthetic subset https://laion-ai.github.io/laion-datasets/laion-aesthetic/laion_aesthetic.html
Recommended usage
Depending on how much data you want to use you can:
- use laion-art which contains the 8M most aesthetic samples (score > 8)
- use laion-aesthetic which contains 120M aesthetic samples (score > 7)
- use the on disk kv to get the full set of tags for the whole 5B samples and do your own custom filtering (or conditioning!) using the whole dataset
Download
Follow https://github.com/rom1504/img2dataset/blob/main/dataset_examples/laion-aesthetic.md for laion aesthetic
https://github.com/rom1504/img2dataset/blob/main/dataset_examples/laion-art.md for laion art
Check https://huggingface.co/datasets/laion/laion2B-multi-aesthetic-tags https://huggingface.co/datasets/laion/laion2B-en-aesthetic-tags https://huggingface.co/datasets/laion/laion1B-nolang-aesthetic-tags for the full set of tags
Demo
In https://rom1504.github.io/clip-retrieval/ I provide a way to guide retrieval by doing (text_query+aesthetic_embedding)/norm. This can be seen as a preview of this aesthetic subsets
Data loader
Same as https://github.com/rom1504/laion-prepro/blob/main/laion5B/usage_guide/dataloader_pytorch.py
Ideas of model to train
- dalle2
- glide
- stylegan
Description
Training set
4000 samples were annotated in a scale from 0 to 10 to be good looking or not.
Aesthetic model
A linear model on top of clip embeddings was then trained and released at https://github.com/LAION-AI/aesthetic-predictor.
https://github.com/JD-P/simulacrabot was used to collect the 4000 samples of the training set
Stats over laion5B
Statistics look like ths
{‘0-1’: ‘1.38M’, ‘1-2’: ‘15.25M’, ‘2-3’: ‘96.31M’, ‘3-4’: ‘237.04M’, ‘4-5’: ‘364.68M’, ‘5-6’: ‘338.19M’, ‘6-7’: ‘149.85M’, ‘7-8’: ‘26.99M’, ‘8-9’: ‘1.69M’, ‘9-10’: ‘0.02M’} for nolang
https://laion-ai.github.io/laion-datasets/laion-aesthetic/laion1B_nolang_aesthetic_distribution.html
{‘0-1’: ‘2.66M’, ‘1-2’: ‘25.62M’, ‘2-3’: ‘147.55M’, ‘3-4’: ‘410.18M’, ‘4-5’: ‘656.38M’, ‘5-6’: ‘601.73M’, ‘6-7’: ‘271.19M’, ‘7-8’: ‘51.43M’, ‘8-9’: ‘3.35M’, ‘9-10’: ‘0.05M’} for 2B-en
https://laion-ai.github.io/laion-datasets/laion-aesthetic/laion2B_en_aesthetic_distribution.html
{‘0-1’: ‘1.77M’, ‘1-2’: ‘21.74M’, ‘2-3’: ‘135.56M’, ‘3-4’: ‘390.73M’, ‘4-5’: ‘640.26M’, ‘5-6’: ‘621.25M’, ‘6-7’: ‘282.89M’, ‘7-8’: ‘50.99M’, ‘8-9’: ‘3.17M’, ‘9-10’: ‘0.05M’} for multi
https://laion-ai.github.io/laion-datasets/laion-aesthetic/laion2B_multi_aesthetic_distribution.html
From these samples, it seems pretty clear that everything above the score 5 is a good part of the dataset from an aesthetic point of view. The samples below that threshold are useful for training clip models but their use is limited for training image generation models.
Sample above 8 are very artistic.
Aesthetic tags
Aesthetic tags are available at https://huggingface.co/datasets/laion/laion2B-multi-aesthetic-tags https://huggingface.co/datasets/laion/laion2B-en-aesthetic-tags https://huggingface.co/datasets/laion/laion1B-nolang-aesthetic-tags
Aesthetic embeddings
Aesthetic embeddings were computed by averaging the clip embeddings for each bucket of score (0-10). They are available at https://github.com/LAION-AI/aesthetic-predictor/tree/main/vit_l_14_embeddings
They can be used to improve retrieval and clip guiding methods. https://rom1504.github.io/clip-retrieval/ show case this with the aeathetic check box.
Aesthetic subset
These subsets of laion5B were selected with various criteria:
- First keep only pwatermark < 0.8 and punsafe < 0.5 using the existing tags
- create a laion-art by selecting only aesthetic score > 8. That’s a 10M subset
- create a laion-aesthetic by selecting only aesthetic score > 7. That’s a 120M subset
Join scripts in laion-prepro
laion-aesthetic is available there: https://huggingface.co/datasets/laion/laion2B-multi-aesthetic https://huggingface.co/datasets/laion/laion2B-en-aesthetic https://huggingface.co/datasets/laion/laion1B-nolang-aesthetic
- en 52M
- multi 51M
- nolang 17M
laion-art is available at https://huggingface.co/datasets/laion/laion-art
Aesthetic ondisk kv
This is a ondisk kv store that can be used to get aesthetic score from hash to score without using any ram.
https://huggingface.co/datasets/laion/laion5B-aesthetic-tags-kv
https://github.com/rom1504/laion-prepro/blob/main/laion5B/aesthetic/aesthetic_kv_usage.py